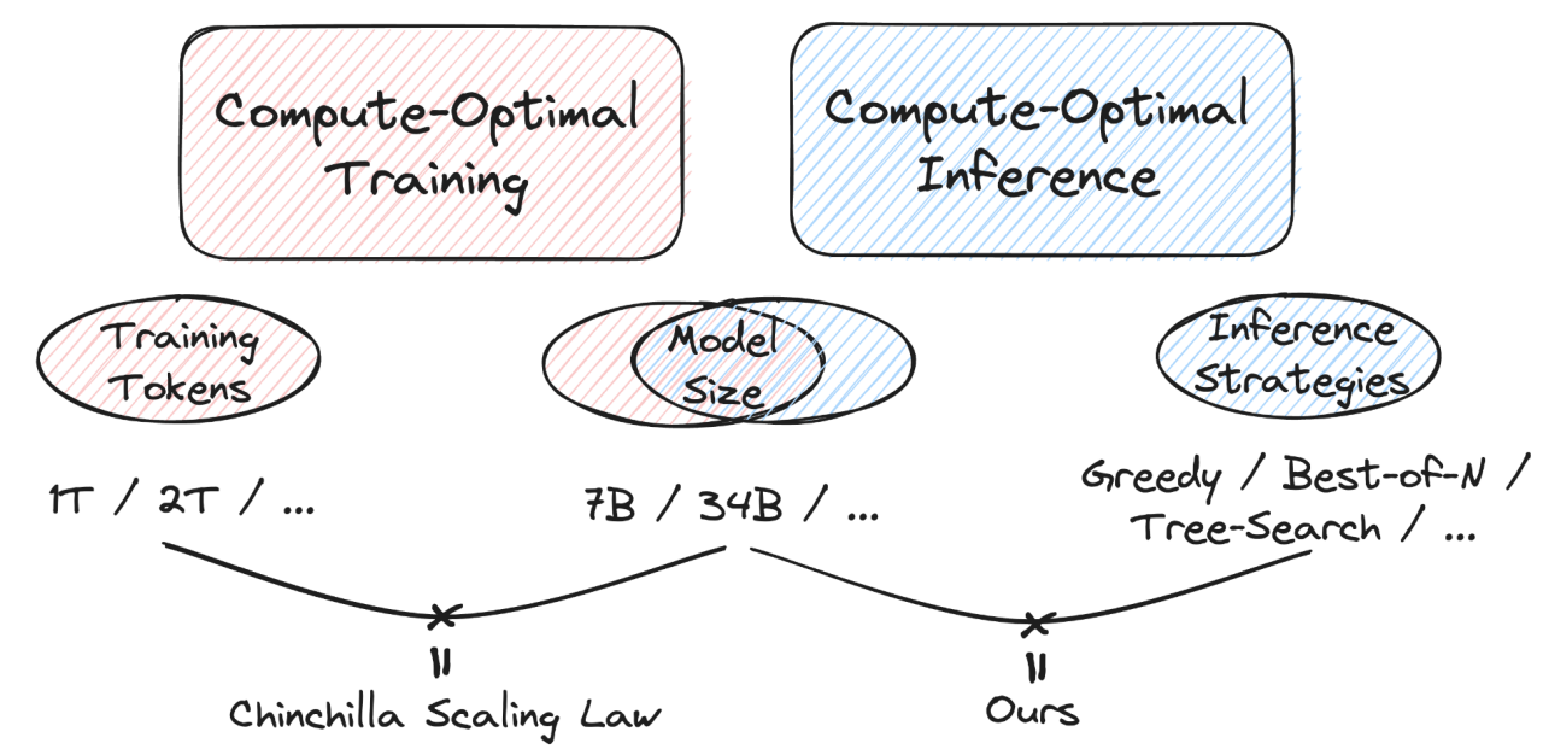
Inference-compute Scaling
More model parameters may lead to high performance on various tasks, but what about scaling the number of decoding tokens in inference? By measuring the amount of computation in FLOPs and studying model performance across different sizes and inference strategies as computation scales up, we can gain a deeper understanding of the effect of inference scaling.
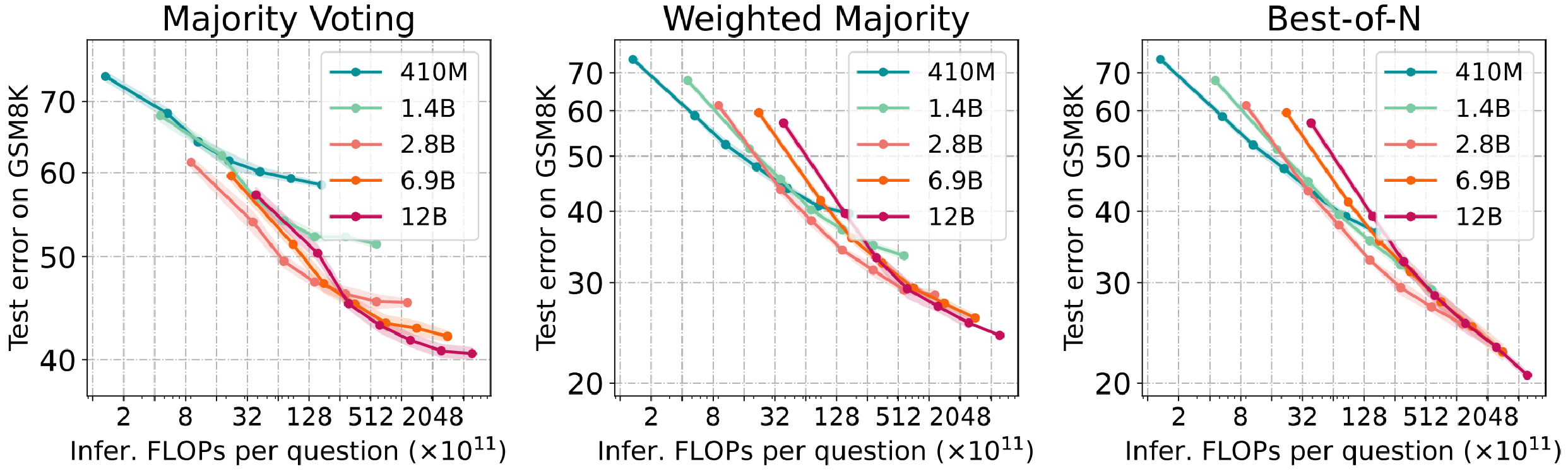
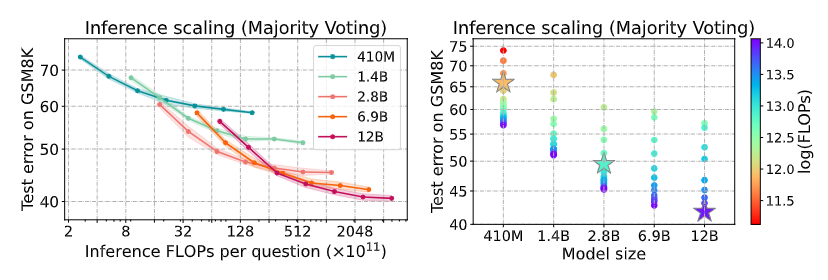
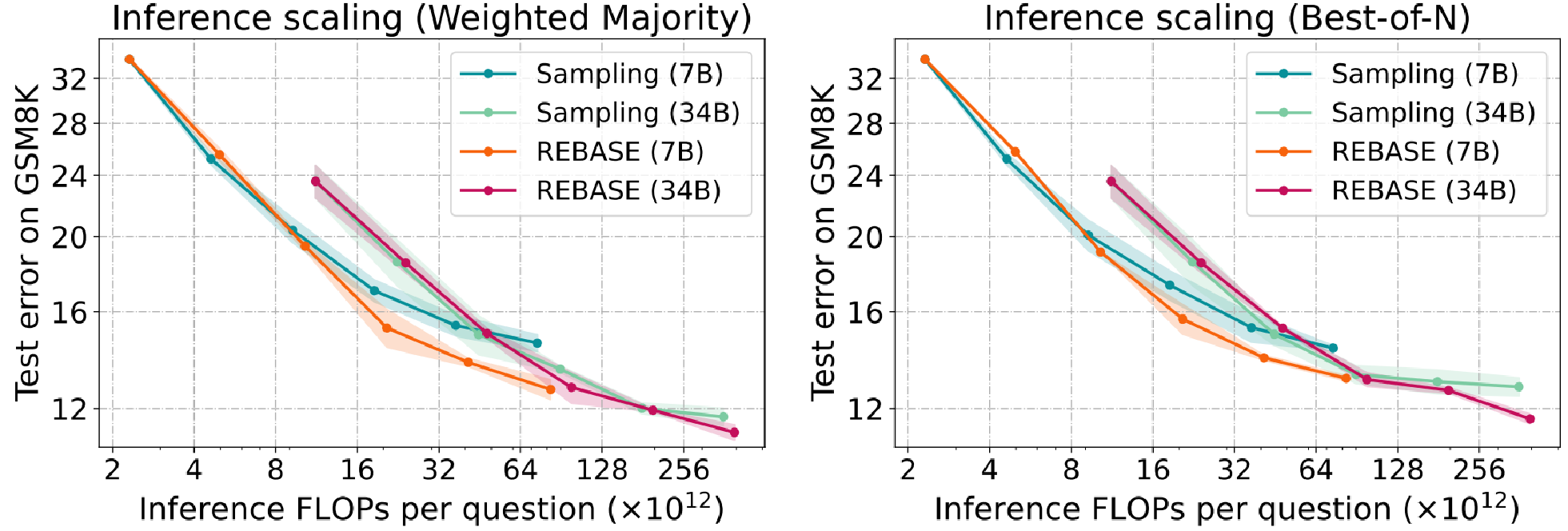
Key findings:
- Scaling inference compute by sampling more solutions leads to growing task performance.
- Across all scenarios, there is an eventual point at which the accuracy will reach a plateau, indicating that additional computational resources yield diminishing returns.
- The ideal model size varies depending on the available computational budget. Notably, smaller models tend to perform better when the compute budget is constrained.
- We also provide theoretical analysis which shows the upperbound and convergence rate in our paper, find more infomation in our paper!